
Did you ever wanted to crawl a list of URLs and figure out which of them are alive? Or what number of external links any of them has? If you did, most probably Screaming Frog SEO Spider was one of the popular choices. Bad news is that free version has a limitation to 500 URLs and paid version costs lots of money (around $150 per year). And worst is that 80% of that crawling functionality can be done in pure Bash.
However, pure Bash has also some limitations, so I decided to spend a day and create a better tool, written in Go. Meet mink, a command-line SEO spider. Mink can crawl a list of URLs and extract useful metrics like HTTP status code, indexibility, number of external and internal links and many many others.
Usage
Here’s a list of options:
Usage of mink:
-d int
Maximum depth for crawling (default 1)
-f string
Format of the output table|csv|tsv (default "table")
-v Write verbose logs
mink reads URLs from STDIN and writes reports to STDOUT. Report can be written in a form of a table, comma-separated values and tab-separated values.
With mink you can understand if page is indexable by search engine or not: mink verifies http status code, canonical url, “noindex” headers and meta tags. Besides that you get many properties of the page like meta description, size, load speed, number of external and internal links and this list is only expanding. Also mink includes all the emails it can find on the pages it crawls.
Here are some examples of usage. In order to crawl the whole website, you can do this:
echo "https://your-website.com" | mink -d 1000 -f csv > report.csv
whereas to crawl a file with an URL per line, do this instead:
cat urls.txt | mink -f csv > report.csv
Probably most viable report format for mink is CSV since you can do fancy things like resource page link building in a Spreadsheet software like Google Docs or LibreOffice.
Example: resource page link building
Resource page link building is a process of getting backinks to your website from resource pages. For that usually you need to find proper resource pages and pitch your resource. Here I will just focus on how you can use mink.
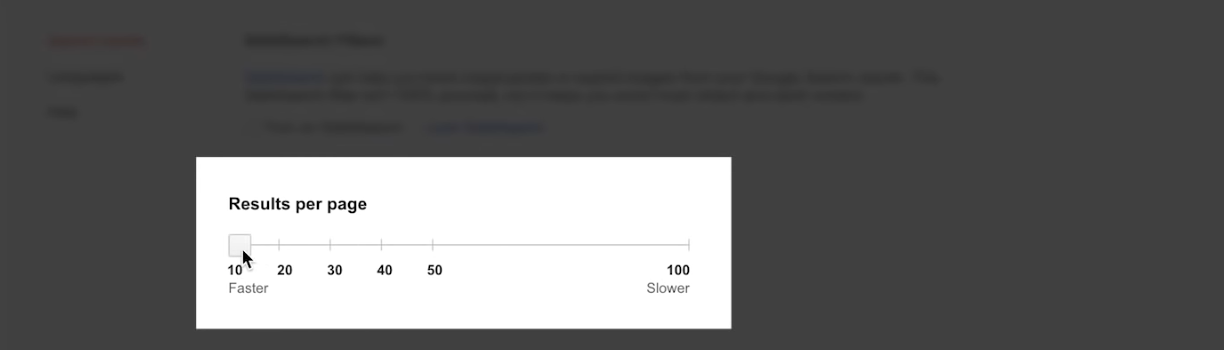
Go to Google Search and change Search Settings in Google and use 100 results per page.
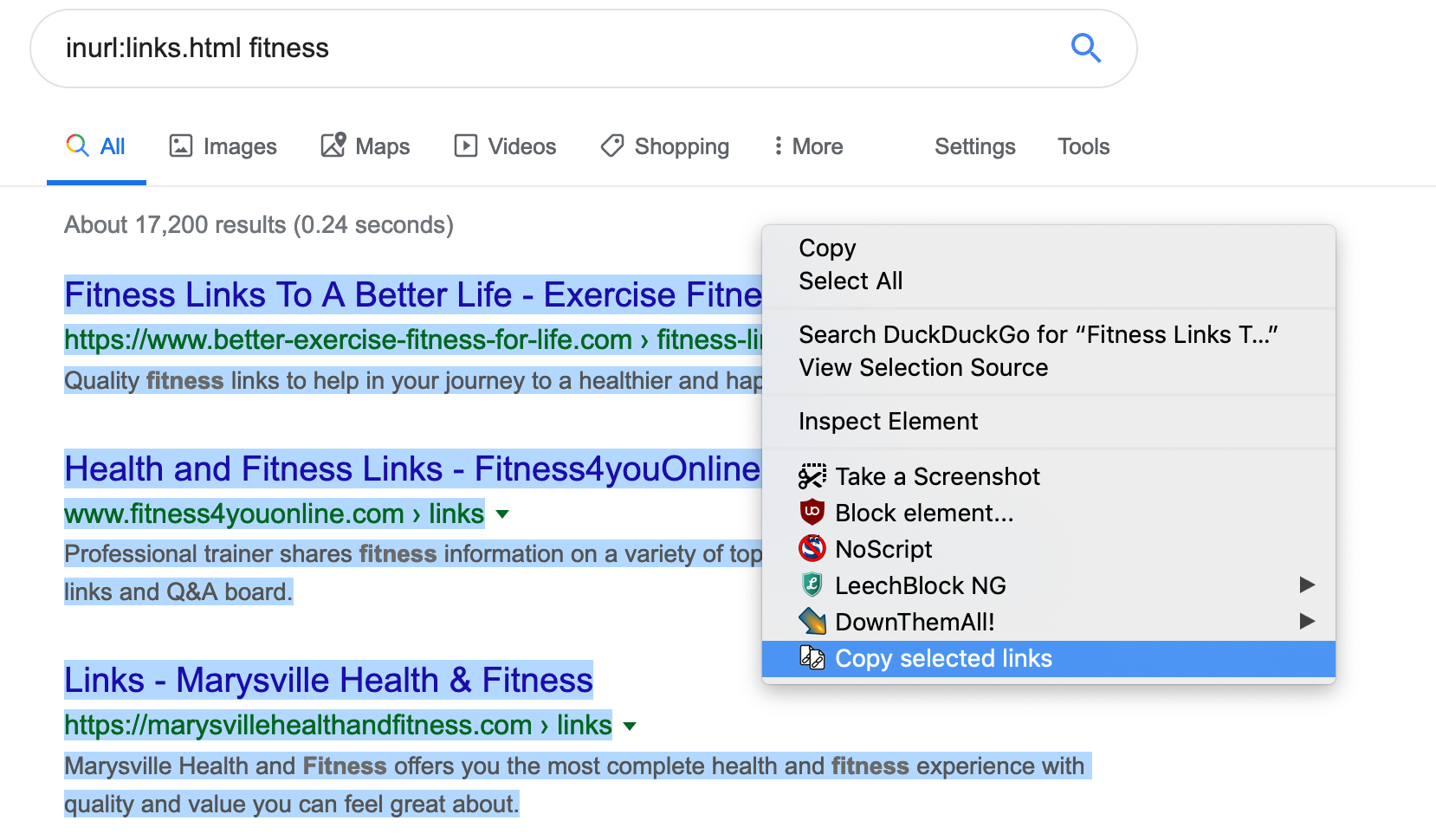
In order to copy real links you can install an extension Don’t track me Google addon (available for Firefox and Chrome) that will convert redirect links to real ones on the page. Also in order to copy the links you can use Copy Selected Links addon (available for Firefox and Chrome).
Now you can search inurl:links.html fitness (or any other keyword). Select page results with mouse and select “Copy selected links” from context menu.
Paste all of the urls to a text file urls.txt and run cat urls.txt | mink -f csv > report.csv in console.
Now go to Google Docs and run File -> Import -> Upload and select the CSV generated by mink. You will see something like this:
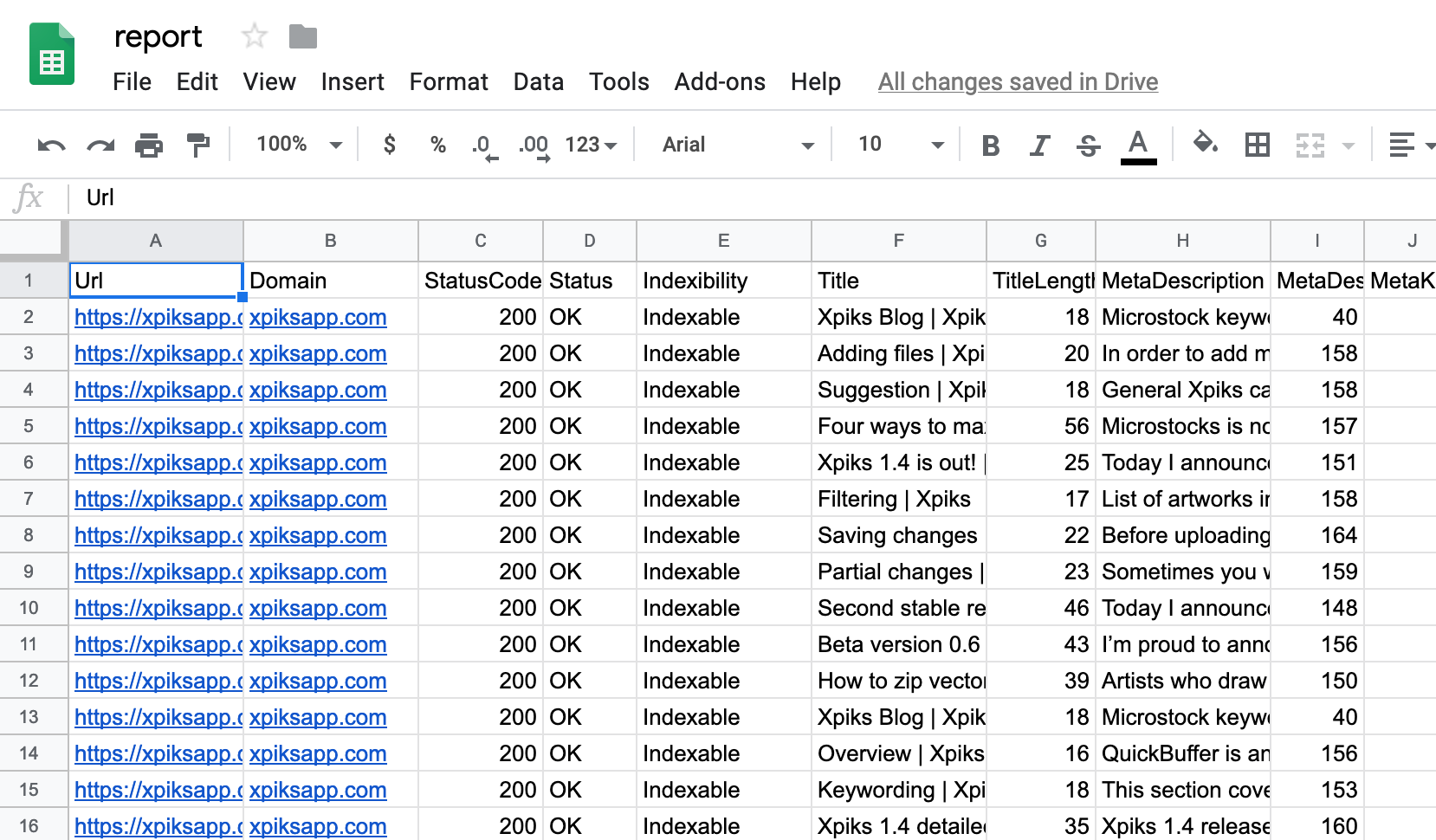
From there you can add filters to the columns and filter out pages that are not Indexable or that are not returning HTTP 200. Then you’re not interested in pages that don’t have external links so you can set a filter to have minimum of 5 external links.
All this information is available in mink and is extremely fast to generate. You might also want to read more about resource page link building on Ahrefs blog.
Contibuting
mink uses such great projects like colly for running the crawl, tablewriter for formatting and goquery to query html.
mink is an open-source project so you can make it better too! Feel free to send a pull request or reach out to me if you have any feature requests.